


Hi all
Recent discussions (e.g. https://www.aavso.org/upcoming-changes-our-infrastructure) about LCG/VStar performance in the context of loading large datasets have led me to think about approaches and return to tickets and ideas that have been on my list for a long time.
Right now, when you ask VStar to load data from AID, you get all available bands for the requested time range.
But as we start to see larger dataset sizes in shorter time spans, loading all available data within a particular time range becomes problematic.
One of the targets of interest in discussion is the X-Ray binary ASASSN-18ey. In just over one month there is in excess of 50,000 Johnson V observations alone, as shown in green below:
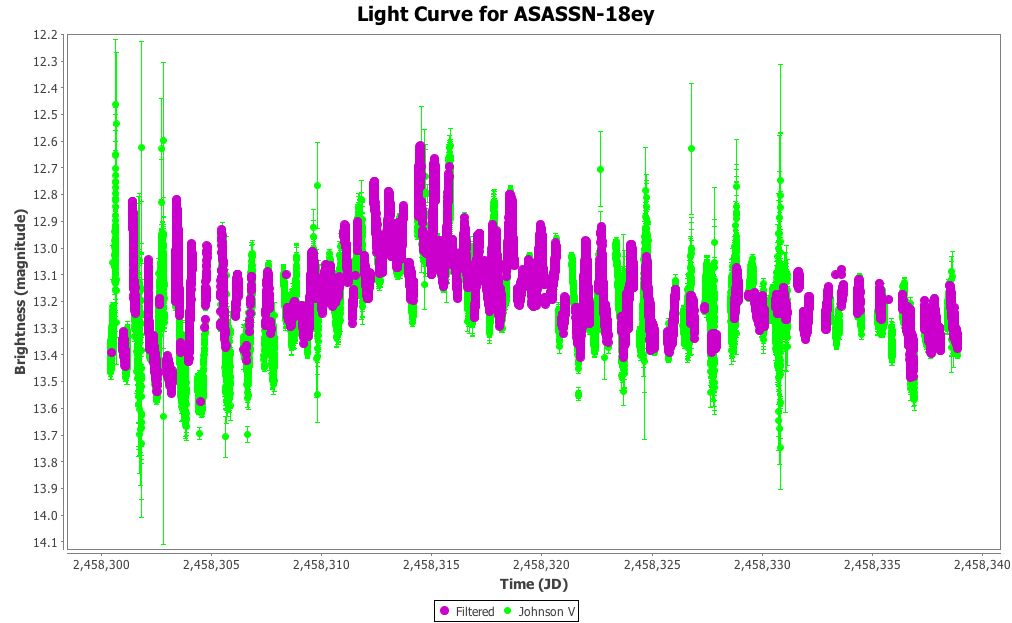
Shown in purple are Johnson V observations with an uncertainty of less than or equal to 0.01: only about half of the data loaded.
Two obvious ways to reduce data load time are to:
- Load only the bands of interest, loading others incrementally via the existing "Add to Current?" mechanism.
- Specify the acceptable uncertainty threshold. This is something Doug Welch requested that we build in from the start in the SuperWASP observation source plugin, due to the high error of some of that data.
Indeed, one can imagine other criteria that would reduce the amount of data to be transferred in an AID web service payload (e.g. obscode). The key point is to make such decisions before any data leaves the AAVSO server. Some of this may be possible via the existing AID web service.
To address the first of these approaches, I'm currently modifying the load from AID dialog to include the ability to specify the bands to be loaded, as follows:

Initially selected bands will probably default to Visual and Johnson V.
Feedback requested.
Therre are other things that can be done, such as varying the web service response type used; see https://sourceforge.net/p/vstar/bugs-and-features/634/
VStar is not a web application so the number of network hops between AAVSO database and web service infrastructure depends upon the user's location, introducing an1other element of variability.
In any case, the question of how to improve the performance of AID data loads in VStar and other AAVSO tools appears to be of particular current interest so I wanted to get a discussion going.
Your constructive criticism is welcome.
David
What I also meant to point out about the dataset above is that currently, when you load all data, e.g. for ASASSN-18ey between say 2458300 and 2458339 you'll get this:
So there's more Unfiltered with Zero-point than Johnson V observations, about 50,000 obs for each of the two bands.
Requesting only Johnson V data means half the load time.
This again underscores the utility of being able to request a subset of bands. So, that will be possible in the next release.
David
But you would be able to also selectively load "Unfiltered with V zeropoint" data , right?
I guess many targets that have these huge datasets had short cadence timeseries photometry campaigns, and there CV and V are often eqully useful. Excluding CV saves time, but is not what you want most of the time.
In the case of ASASSN-18ey, it is not unusual that observers submit data with a cadence of 1/minute or even faster. This might be useful for some analysis, but not for others, so what would really help would be time domain averaging on the server (for data submitted per observer, not across observers!) , but I see that this is nothing that can be done in a short time.
CS
HB
Yes, for sure. The ability to selectively load data for different bands, and then also subsequently add to what has been loaded (already permitted) is what I'm developing (and shown in initial post's screenshot above).
I had more or less the same thought as you about time domain averaging per observer on the server and along similar lines was wondering about:
The other obvious ones I've mentioned are: observer code and error (uncertainty) range.
David
Ah I see..I was just worried because the screnshot didn't include "CV" filter.
Yeah this is tricky., and sometimes you don't even know from the start how many datapoints may be in the DB for your query. Databases query frontends lilke SIMBAD allow to specify a maximum number of returned rows (with a reasonable default), and you'll get a warning message when there's more in the result than what you asked for. I think that would be a nice feature to have to start with. I think that's relatively easy to do on the SQL side.
Now if you then find that your initial choice of max rows is not sufficient, the time sampling you suggested would already be very useful IMHO. It has the advantage of only returning actual measurements (and not aggregated/averaged synthetic measurements that are quite a bit more difficult (what to do with airmass? computing the error of the averaged point...what about the comp and check star values, what about the notes field.....ufffff)). Averaging or fitting could be left for a later version perhaps (developer code speak for: I hope this is not necessary and people will forget about this feature request :-) ).
Loading datasets incrementally by error range is a nice idea, but I have a feeling that this value is often not very well maintained by some observers (tension between reported error and observed scatter compared to what other observers found). Those who report the smallest error are sometimes the most problematic...
Loading datasets incrementally by observers : this would also help a lot. It would be super-useful if you had a button "Load by Observers", you would then get a list of all the observers and the number of their respective datapoints in the resultsets (and the filters they used) so basically what is displayed in the lower half of the new Light curve generator. You would then (de)select observers and load the desired subset.
CS
HB
It's been a busy couple of days so apologies for the delay.
I like your idea of a "warning message when there's more in the result than what you asked for". The web service provides observation count information and indeed this info is used internally This would be worth exploring. Do you think the maximum should be set as a preference or for each observation load as part of the AID dialog? I'm thinking the second.
I'm glad you agree with me about the utility of time sampling.
I kniow what you mean about "left for a later version perhaps". :)
Load by observers makes sense too, as you say. That may require an enhancement to the web service.
Another thought I've had, again requiring change to the web service, is to allow the user to specify which fields to be returned in the response, e.g. just JD, mag, error, obs code.
It seems like there's a lot we can do by working better with the web service or requesting enhancement of it.
Also, I'm tracking key ideas here:
https://sourceforge.net/p/vstar/bugs-and-features/636/
David
> Do you think the maximum should be set as a preference or for each observation load
>as part of the AID dialog? I'm thinking the second
As part of the dialog, yes. The Preferences could have an entry for the default value perhaps.
> I'm glad you agree with me about the utility of time sampling.
Yup, and perhaps even a really radical method might work or at least help in the meantime where you return only ever nth observation (in the trivial sense of numeric_ID MOD n == 0). At least this would allow people to get a "bird's eye view"/big picture of huge datasets with a semi random selection.
> Another thought I've had, again requiring change to the web service, is to allow the user to specify which fields to be returned in the response, e.g. just JD, mag, error, obs code.
That sounds very useful as well to me!!Certainly preferrable to drop unused columns than to drop observations.
CS
HB
Thanks for the feedback. :)
I'll probably want more.
David